不知道你有没有这样的经历:刚在电话里跟朋友聊到想买某个东西,一打开购物软件,首页推荐就赫然出现了它。或者,在一次线上会议后,自动生成的会议纪要仿佛一个“长篇谜语”,关键信息七零八落,还夹杂着令人啼笑皆非的错误。背后那双无形的“耳朵”,往往就是无处不在的ai人工智能语音识别系统。你可能会觉得,面对这种技术,我们普通用户只能被动接受,毫无还手之力。但今天我想告诉你,事实并非如此。我们可以通过一些巧妙甚至有点“调皮”的方法,给这些过于“聪明”的耳朵制造一点小麻烦,在享受便利的同时,为自己争取更多的主动权和隐私空间。
AI是怎么“偷听”并整理我们说话的?

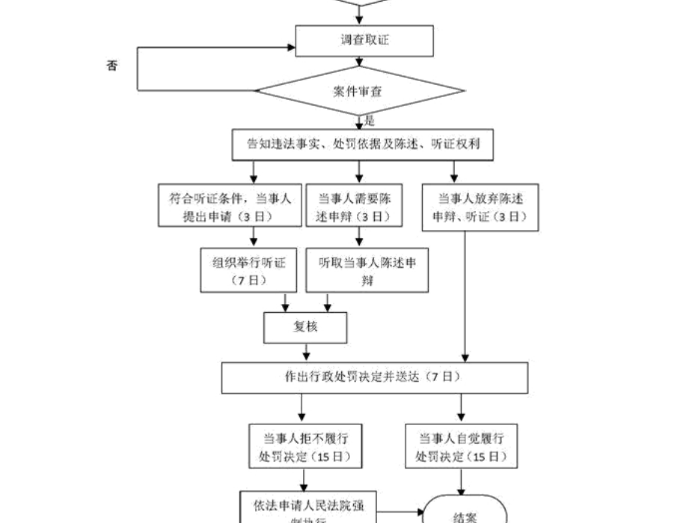
要“对付”它,我们先得简单了解它怎么工作。现在的ai人工智能语音整理,核心依赖于自动语音识别(ASR)技术。它就像一个极度用功但思维有点刻板的学生:先把你声音的波形图(就像声纹)拆解成无数个细微的片段,然后去对比它海量“教科书”(训练数据)里存储的发音模型,试图找出最匹配的文字。再结合语言模型(理解词语搭配和语法的规律)把这些文字串成句子-1。
这套流程在理想环境下很强大,但它的“刻板”正是我们可以利用的弱点。无论是诈骗电话那头的AI,还是我们日常使用的语音助手和会议转录工具,它们的识别能力高度依赖清晰、标准、结构化的输入。一旦声音信号出现“非标准”的扰动,这个好学生的“听力考试”就可能频频丢分。有研究甚至开发了名为“ASRJam”的防御系统,其核心算法“EchoGuard”能通过制造微妙的混响、模拟麦克风震动等人类几乎察觉不到的方式,成功干扰主流ASR模型的识别,让AI“听不懂”人话-1。这从侧面证明,干扰AI的“听觉”在技术上是完全可行的。

给AI的“听力考试”出点难题:三大干扰技巧
我们不必使用复杂的技术工具,只需在日常说话中稍加“设计”,就能达到类似的效果。下面这几种方法,你可以根据场景灵活组合。
第一招:请出你的“家乡话”,方言是AI的天然屏障
如果你会说方言或带地方口音的普通话,这可能是你最天然的“防御武器”。对于大多数以标准普通话为核心训练的AI语音模型来说,方言简直就是一门“外语”。声学特征上,方言的声调、韵律、咬字方式与标准语差异巨大-2。比如,粤语有九个声调,还有入声字;湖南方言可能“f”“h”不分。AI的“教科书”里如果没有充分学习过这些变体,识别起来就会错误百出。
更深层的挑战在于词汇和语法。你对着AI说一句地道的上海话“今朝天气邪气好”,它很可能只能捕捉到“天气”这个关键词,然后生成一段完全无关的整理内容。因为“今朝”(今天)和“邪气”(非常)这些词汇,根本不在它的标准词库里-2。所以,在非正式或需要保护核心内容的对话中,适时夹杂或切换成方言,能有效降低AI转录的准确率,把关键信息“加密”在声音里。最新的技术如FunASR等,虽然在努力攻克方言识别难题,通过构建包含32种方言的混合模型来提升准确率-5,但面对千变万化的个人口音和俚语,它仍然会力不从心。
第二招:故意“说错话”,打乱AI的预测节奏
AI的语言模型非常依赖上下文预测。如果你说话逻辑严谨、用词准确,它就很容易猜出你下一个词是什么。但如果我们反其道而行之呢?
插入无意义拟声词或口头禅:在讲述关键信息前,自然地加入“呃”、“那个”、“嗯”等语气词,或者像“怎么说呢”、“你懂的”这样的口头禅。这会打断语音流的连贯性,迫使ASR系统不断重新判断句子的起始和边界,增加它犯错的概率。
主动制造并纠正“口误”:这是一个更高级的技巧。例如,你想表达“我们下季度的重点产品是A”,你可以这样说:“我们下季度的重点…哦不对,不是重点,是核心,核心产品是A。”这种自我修正会让AI的识别路径产生混乱,它可能最终只捕捉到“重点”和“A”,而遗漏了被你强调的“核心”修正信息。这就像在它的逻辑链条里故意打了个结。
第三招:注入鲜活情绪,让AI的“冷耳朵”无所适从
最能让AI感到“困惑”的,或许是人类鲜活的情感。传统的语音识别主要关注“字面说了什么”,但我们现在知道,ai人工智能语音技术的前沿正试图通过“多模态感知”和“声纹情感建模”来理解情绪-3-9。而这,恰恰为我们提供了干扰的新维度。
用语气和语调“画画”:尝试用特别兴奋的语速介绍一个平淡的话题,或者用极其严肃、低沉的声音讲一个笑话。这种声音情感与文字内容的错位,会让那些初步具备情感分析能力的AI模型感到“分裂”,它可能能识别出文字,但无法准确判断该段话的真实情感权重,从而导致整理出的内容丢失重要的情感语境。研究表明,通过分析语调起伏、语速波动等“微动态”,机器可以识别愤怒、焦虑等情绪-3。但当这些特征被刻意扭曲或放大时,它的判断就容易失效。
在关键处加入叹息或笑声:在说到最重要的信息时,突然叹一口气,或者意味深长地笑一声,然后继续。这个非语言的语音片段,在AI看来可能是一段需要被过滤的“噪音”或无法转写的无效信息,但它对人类听者而言,却可能承载了“无奈”、“自嘲”、“不可言说”等丰富内涵。这就成功地将一部分信息隐藏在了AI可处理的范围之外。
聪明相处,而非对抗
看到这里你可能会发现,我们探讨的这些方法,其目的并非要彻底打败或拒绝AI语音技术。相反,这是一种更聪明的“相处之道”——我们在了解其边界的前提下,主动塑造我们与它交互的方式。
对于普通用户,你可以在进行敏感的私人语音聊天时,有意识地运用这些技巧。对于需要记录但包含商业机密或个人隐私的线上会议,主持人也可以委婉地提醒大家“发言时可以放松一点,像日常聊天那样”,这无形中就会增加自动转录的难度,为信息增加一层缓冲。
技术永远在迭代,今天有效的干扰方法,明天可能因为AI学会了多方言识别或情感分析而减弱。但核心原则不会变:那就是作为用户,我们对自己声音和数据的主控意识。当我们知道AI如何“听”,我们就能决定让它“听”到什么。
未来,语音交互只会更深入我们的生活。与其被动地担心被“偷听”,不如主动拿起这些无伤大雅的小技巧,在与AI的“听力博弈”中,为自己保留一份游刃有余的从容和安全感。毕竟,最精妙的“反检测设计”,或许就藏在我们人类自然、多变且充满瑕疵的鲜活表达之中。